This will be my final post in the blog (so sad :( ). In this week's blog, I will be going over sorting and efficiency of algorithms.
Sorting...
If I asked you to sort a list of integers from least to greatest, how would you do it? Of course! You just - uh.... never mind. It's actually quite difficult to come up with an algorithm in your head because we're accustomed to compute seemingly simple tasks subconsciously.
When I was first asked to come up with my own sorting algorithm prior to being introduced to any of the basic ones, it was really difficult. I pulled a sheet of paper and started to write down an unsorted list of integers. Then, I used the process of elimination, starting with the lowest integer and I drew an arrow showing that I moved the lowest number to the beginning of the list. I then ignored the integer that I moved and went through the same selection process again.
It turns out that the algorithm that I came up with was selection sort. Like selection sort, there are other algorithms of sorting a list of numbers.
Below is a list of a few sorting algorithms, with a small description of each algorithm:
- Bubble sort
- Merge sort
- Timsort - Python uses this algorithm.
- Insertion sort
- Quick sort
Efficiency and Time Complexity...
As there are many ways to sort a list of integers, some of the above algorithms can be quite slow, or rather, inefficient. How do we computer scientists express how slow or fast an algorithm is? One way is to use Big-Oh notation to do this.
If f(x) is some function, then O(f(x)) means that some function grows no faster than f(x). For example, for any natural number n, as n approaches infinity, n^3 grows faster than n^2. So, we can write this as:
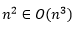
In other words, we could think of that as the growth or the order of n^3 is an upper bound of the growth or the order of n^2.
How do we come up with these functions for sorting algorithms? One method is to measure the number of steps ignoring the size of the list.
I'll summarize a few types of functions representing the number of steps of any case.
Let c be any positive number, and n be a natural number.
- Constant - f(x) = c. A sorting algorithm's behavior is constant if the algorithm performs the same amount of steps regardless of input. This is undoubtedly the best possible performance for any algorithm. We generally represent an algorithm like this with O(1) (it doesn't matter what number we choose for a constant function since we're representing growth. Since f(x) = 1 doesn't grow as x approaches infinity, it's the same case for any other positive constant. So something like O(2) is also acceptable).
- Logarithmic - f(n) = c lg n (where lg n is log n, where log is base 2). You would usually see this for any "divide and conquer" algorithms. log n is the number of times you can divide n in half before reaching 1.
- Linear - f(n) = cn. A for loop that grows linearly can be represented as O(n). For example, for i in range(1, i + 1) grows linearly.
- Quadratic - f(n) = cn^2. A for loop that is O(n) that has another for loop that is O(n) can be represented as O(n^2). A for loop that has any sort of multiplicative increment may also be considered as O(n^2), but it depends on the increment itself.
- Cubic and Exponential - f(n) = cn^3, f(n) = ca^n, where a is some positive number. You might see this as a mix of linear and quadratic loops.
So how do we represent the 'worst case' performance/complexity (how long it takes to execute an algorithm given some input) using big-Oh? Well, we simply observe the number of steps that some algorithm takes regardless of the size of the input, and we use our knowledge to construct a function that represents the number of steps. Eventually, we will get some function representing the number of steps of an algorithm that can have one or more terms.
For example, let f(n) = n^3 + n^2 + 2 represent the number of steps given an input size n. As n -> infinity (because the worst case is usually the result of a large size of input), we could see that n^2 + 2 becomes less significant, while n^3 takes more precedence, hence we say that this function is O(n^3).
However, big-O is usually associated with the "worst case" scenario, however, this isn't always true. O(n^4) is also a valid representation of f(n), but it's not exactly the tightest bound, and you can think of O(n^4) as an overestimation of f(n).
Big-O simply represents an upperbound of f(n) and not always the worst case scenario time complexity of an algorithm! Remember that!
Then we could get into big omega, which represents a lowerbound and big theta, which represents tight bound of some time complexity of an algorithm. However, that's outside the scope of this course, and you shall discover it without me!
It's been fun. I hope you have enjoyed my SLOGs and I wish you well in your computer science careers!
GR